ProvDIVE: PROV Derivation Inspection and Visual Exploration
Problem
Applications which working with large amounts of data, can also produce large amounts of of Provenance derivations. Recently, a method to reconstruct provenance derivations from diffused social media messages was presented. We scaled the reconstruction approach up and have to deal now but derivations in the amount of several hundred thousands to millions. In order to improve the reconstruction algorithm, the huge amount needs to be understood and verified. A manual inspection of individual derivations is therefore necessary.
Social media use-case
Given all the derivations only some of them might be from interest for the user. These could be messages containing particular keywords, created by specific authors or diffused within a given timespan.
Even after filtering, a manual inspection of individual derivations might not be possible due to the possibly large remaining amount. Therefore messages from the remaining graph can be summarized or aggregated based on the messages or the derivations properties. Each summarized subgraph entails messages with particular properties and can be considered for filtering as well.
The ProvDIVE framework
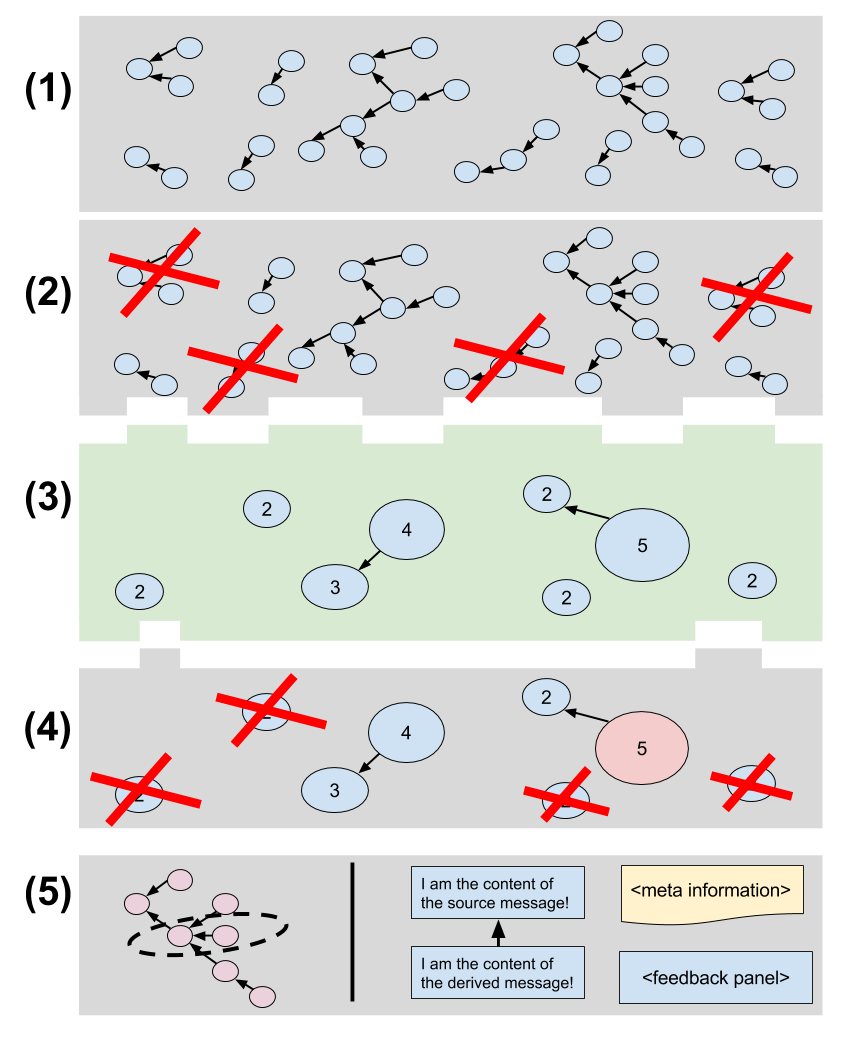
The framework tries to solve the stated problem by implementing generic algorithms based on the description of our use-case. The Figure shows how this might look like.
(1) The given input: W3C PROV derivations(2) Filter PROV entities from the raw graph based on their properties.
(3) Summarizing the remaining entities. The user can choose between different summarization techniques, depending on on her/his needs respectively the input data.
(4) Filtering summarized subgraphs, based on their properties.
(5) A drill-down functionality, so the user can zoom into subgraphs he/she is interested in.
Display a concrete derivation in detail, with associated meta information encoded as Derivation properties, in order to verify it. The assessment can be given via direct feedback, e.g a Likert scale. For the social media use case which covers short messages, the full content of the source entity and the derived entity can be shown.